

AI Alignment: Why Solving It Is Impossible | The List of Unsolvable Alignment Problems
Why AI alignment theory will never provide a solution to AI's most difficult problem.


Why is AI Alignment Impossible?
There isn’t merely one obstacle that must be overcome to achieve successful alignment, but a myriad of problems that aren’t just hard, but have no conceivable solution as they are either logically unsolvable or undefinable.
Those who purport that alignment is solvable generally do so by advancing past these unsolvable components to present us with a “solution” that somehow must materialize without ever addressing how these unsolvable components are resolved.
The problems of alignment apply to both the AI we have today as well as theoretical powerful AI such as AGI or ASI. For the purpose of addressing the alignment arguments, we won’t debate in this context if AGI or ASI are achievable, we will simply address the premise of alignment under this assumption.
What Are the General Categories of Problems?
What are the key factors that make alignment unsolvable? We will elaborate in detail on each of these as we progress further.
General problems for alignment
Lacks a falsifiable definition
There is no way to prove we have completed the goal
There is no defined criteria or rules to test for success
Aligning to humanity’s values
Our values are amorphous, unaligned, and interdependent
There is no agreement how to define or implement this goal
AI must have predictable behavior
The nature of intelligence is unpredictable
AI should benefit all of humanity
Behavior is decided by those who build it resulting in authoritarian governance conflicts.
Additional problems for AGI/ASI
A solution must be found before we achieve AGI
We race toward AGI as fast as possible
AI must always be corrigible to fix incorrect behavior
Must not be corrigible to prevent tampering or incorrect modifications
AI must solve the alignment problems too hard for humans to solve
We must trust the machines that we cannot trust
The solution must be perfect
We must prove we have thought of everything, before turning on the machine built to think of everything we cannot.

We have fundamental root problems that are either undefinable goals or logical contradictions. The concise set of contradictory and nebulous abstract obstacles to alignment could be described as the following:
“Alignment, which we cannot define, will be solved by rules on which none of us agree, based on values that exist in conflict, for a future technology that we do not know how to build, which we could never fully understand, must be provably perfect to prevent unpredictable and untestable scenarios for failure, of a machine whose entire purpose is to outsmart all of us and think of all possibilities that we did not.”
We have defined nothing solvable and built the entire theory on top of conflicting concepts. This is a tower of logical paradoxes. Logical paradoxes are not solvable, but they can be invalidated. What that would mean is that our fundamental understanding or premise is wrong.
Either AI requires no alignment, as we are wrong about its power-seeking nature, or we are wrong about the feasibility of even building such powerful machines, or we are wrong about alignment being a solution. There are no other options, we must be wrong about something.
What Is AI Alignment?
Alignment is described as the method to ensure that the behavior of AI systems performs in a way that is expected by humans and is congruent with human values and goals.
Alignment must ensure that AI is obedient to human requests, but disobedient to human requests that would cause harm. We should not be allowed to use its capability to harm each other.
Due to the nebulous definition of “harm”, alignment has also encapsulated nearly every idea of what society should be. As a result, alignment begins to adopt goals that are more closely related to social engineering. In some sense, alignment has already become unaligned from its intended purpose.
Essentially, implementation of alignment theory begins to converge towards three high-level facets:
Reject harmful requests
Execute requests such that they align to human interpretation
Social engineering the utopian society

Goal Optimization Results in Undesirable Outcomes - Instrumental Convergence
When humans are given a simple set of instructions, they intuit all of the details not explicitly stated. They are able to do so through mutually understood societal values. If you order a table to be delivered from a store, the store doesn’t take one from your neighbor and give it to you simply because it would be more efficient. However, AI that optimizes for the task at hand may take unpredictable and undesirable actions to complete that task.

Furthermore, the AI may optimize in complex ways not evident by a specific requested task, as the AI may take actions to optimize many tasks or goals that have common underlying needs. Such actions might include resource and power acquisition, self improvements, replication of AI instances, or other activities without regard to the potential for those actions to negatively impact other facets of society or human needs. This concept is called instrumental convergence.
Extremely powerful AI, given immense capability, could take catastrophic actions to resolve given tasks. Therefore, the AI must apply some form of limits to its own capabilities where they are in conflict with our own values and devise alternative methods that solve the goal without conflict.
It is the goal of alignment to define the expected behaviors in this regard, so that the AI doesn’t consume the surface of the Earth for the material to build the things we request of it. Or simply inject humanity with nanobot-replicating drugs as the means to promote societal bliss. AI with the power to do anything may solve problems and goals in the most unexpected and undesirable ways.
We Humans Will Also Optimize for Undesirable Outcomes
This concept is not novel. The problems with unexpected optimizations are also human problems of exactly the type I observed in my former corporate jobs, where executives attempt to put in place goals for employees. The employees would optimize for achieving those goals resulting in not achieving what the executives thought they were incentivizing. The problem with AI is that orders of magnitude are more at stake when we miss the mark.
We Are Myopically Focused on Formulas Ignoring the Goal Is Flawed
How does alignment attempt to remedy these problems? The difficult part of alignment is typically considered to be describing the desired behaviors through some type of utility or reward functions, or through some method of AI training.

Everyone is focused on the formulas and methods, but have neglected to comprehend that the proposed solution — humanity’s values and goals — could only result in what would be described as unaligned AI, even if a method is found that allows AI to successfully adopt those implied behaviors.
AI Alignment: Solved by Humanity’s Values?
The solution to an all-powerful AI is that it only uses its capabilities to help humanity in precisely the ways we expect it to do so. In order to achieve these types of outcomes, alignment attempts to instill humanity’s value system into the machine.
The premise is that if the machine adopts humanity’s values, then it will have the same perceptions as humans in regards to things we value and actions we consider positive or negative. Conceptually, things like protecting life from harm, promoting peace, well-being and happiness, and protecting or stabilizing the environment, concepts of fairness and justice, etc.
Humanity’s Values Are in Conflict
However, there is a major problem with this alignment theory. Humanity’s values are in conflict. We are ourselves unaligned. We don’t agree on any of the criteria for which we would align AI.
We see this playing out already with simple LLMs. Researchers seem surprised when LLMs exhibit undesirable behavior. However, LLMs are uncomfortable mirrors of our human society. What we perceive as unalignment is merely a reflection of the very values that we assume to be the solution.

Every alignment problem is a human problem. Every scenario is, in fact, a replication of human behavior. For example, the problem of the AI solving goals using undesirable methods is not novel. Humans do this. We just call it cheating. The irony is that we are supposedly going to solve alignment by applying humanity’s values and goals, but these same values and goals also fail for humans. Want to see humans cheat more? Just give them more power and watch what they do.
“I continue to be fascinated by the industry that is focused solely on creating machines to reason like humans and then they are shocked when the machines ‘reason’ like humans.”
— Notes From the Desk #14, AI Bot lies and surprises researchers
Humans Are Misaligned While Following the Same Goals
Human misalignment is not apparent either. Most humans don’t have goals to harm each other, yet their actions often result in such consequences. Again, if we just give the AI our values and goals everything will be fine. However, if this were to be true, then how do we explain the harm we do to ourselves?

An alignment compass comes to form where pre-existing ideological and political views are simply represented through “alignment” concepts. These views don’t become any more solvable than they were prior.
It is impossible to align to mutually exclusive views of how the world should be. Alignment becomes assignment of a uniform view, forcing compliance. This is not a problem for those who define alignment, as they stand on top of moral hubris.

The debate on what constitutes 'safe' AI and its allowable actions, as well as its impact on others, is of precisely the same value conflicts that exist now among the diverse political and cultural factions of civilization.
Government is essentially the conceptual AI alignment test. How many of you are happy with your government? How well has it remained aligned with the people? How many want to give it more power? We can’t even align humans, who theoretically are already predisposed to be aligned, but somehow we will successfully align AI? Humans operating under humanity’s value system still engage in war.
AI Alignment: Choosing the Correct Values
Considering all the complexities and conflicts mentioned with human values, some perceive the solution as simply choosing the correct human values. Even if we advance past the unsolvable problem of choosing and agreeing on the values and their properties, we still have an unsurmountable problem.
The human value system is composed of inseparable, interdependent properties. We often state, for simplicity, that human values are in conflict; however, it may be more correct to state that we have the same values but different value judgements or parameters.
Even Universally Positive Perceived Goals Are in Conflict
For example, take two of the most simplistic concepts that humans value: liberty and safety. Isolated, each is a positive value. However, it is the interplay between these values that creates the perceived conflict. Every individual wants to experience both liberty and safety, but every single instance where they must be evaluated for a situation in which both are relevant, we disagree as to which should carry the greater weight to resolve to a decision.
Furthermore, it may be the case that there are no negative values to remove. Is greed a value expressed by some people? Or is it rather nothing more than the same values everyone else shares, expressed differently with different priorities? Is it greed to have maximum liberty, as I can do whatever I want? Or is it greed to have maximum safety, as others must be forced to take actions to protect me? Every single “value” can be expressed as precisely its inverse.
Our Values Are Too Complex to Meaningfully Deconstruct
The hard part isn’t selecting the values; it is determining how each are expressed within the infinite bounds of reality. Potentially, there are not enough words to sufficiently describe how values shape our society, as the origin is deeper than our own conscious thoughts.
Potentially, the most disturbing aspect that must be considered is that all of the destructive tendencies we see in society are not simply from the “wrong” values, but are a product of our common values that, when interacting within a complex configuration of environmental values, results in undesirable outcomes. But the problem is that it may be impossible to manipulate our human “algorithms” to “fix” these undesirables without losing the desirable outcomes. Nature is complex, and many things have reasons that are not obvious.
Human Biology Is Instrumental in Human Values
We intuit many values simply from our own mortality, a mechanism of survival. Much of our values are constructed around this base need. A machine does not exist in the same environment. Our values are more than just the texts we write, but something that originates beyond our own conscious self-directed mind.
As living beings, some rules are innate to our biological existence. Mortality gives meaning and value to our existence, on top of which we construct many of our moral and ethical foundations. Without the fragile nature of our existence, many of our values may be incomprehensible.
Social Bonds Are an Essential Component of Human Cooperation
Social bonds are also part of our alignment. When social bonds are not at risk, we easily become misaligned. Our behaviors often deteriorate the more anonymous we become in society.
All of our values or ethics could potentially be described as emergent behavior built on top of the primal need for social bonds. If this is the case, it would be a major mistake to assume these rules will operate without that condition. They are not the prime rule, but simply a product of the prime rule.
Social bonds are strengthened through sharing of unique experiences built on top of common experiences. They also are the source of our own alignment and conflict. Social bonds cause bias for the group, which is necessary for evolutionary survival. Is it possible for an entity with no vulnerabilities to have empathy? Is empathy derived from our weakness, which also bonds us together to protect each other?

What keeps humans “contained” or “aligned” is that we have vulnerabilities. There is a cost to “bad” behavior. During training, in childhood, bad behavior is management due to the disproportionate power of adults over children. As an adult, it is managed as a cost of membership in society, the social bonding. If AI is to be human-like, we are removing the human constraints if we make it more powerful. We know what type of behavior unchecked power leads to in humanity.
AI Safety Aligns With AI Predictability
A popular attempt to express AI safety or risk is by a metric known as p(doom). However, no scientific methodology is utilized for its computation, making it of no value for understanding risk. The conceptual expression of risk can be stated to be risk = unpredictability * capability. If we want safer models, either we limit their capability or we design them to have predictable behavior.
“Another consequence of computational irreducibility has to do with trying to ensure things about the behavior of a system. Let’s say one wants to set up an AI so it’ll “never do anything bad”. One might imagine that one could just come up with particular rules that ensure this. But as soon as the behavior of the system (or its environment) is computationally irreducible one will never be able to guarantee what will happen in the system. Yes, there may be particular computationally reducible features one can be sure about. But in general computational irreducibility implies that there’ll always be a “possibility of surprise” or the potential for “unintended consequences”. And the only way to systematically avoid this is to make the system not computationally irreducible—which means it can’t make use of the full power of computation.”
Wolfram is stating that AI systems are too complex to compute or predict outcomes. We will never have predictability from such systems unless we severely limit their capabilities.
We cannot predict the behavior any other human. We can’t predict the behavior of even lesser-intelligent animals. Alignment theory requires that we have predictability. However, humans and their values would need to be turned into algorithms and formulas, but human existence is computationally irreducible. Physical existence is the computational machine, and the only way to know an outcome is to observe the result.
Medicine Is an Unpredictable Science Like AI. It Is Not Safe.
The closest “science” we may have to AI alignment is medicine. Where we don’t have math and formulas that can precisely predict outcomes. Therefore, it is progress by experimentation, observation and some heuristics. The result is that medicine is not “safe”. We don’t have high confidence or provable outcomes. We only find it acceptable because we at least can somewhat contain the possible bounds of risk, even if we cannot predict the exact consequence.
Intelligence Is Computationally Irreducible - Behavior Is Not Predictable
If the behaviors we wish to install into the AI systems are themselves computationally irreducible, then there is no path that leads to computable formulas or predictable outcomes. It is a dead end for alignment theory, as it is impossible to know what powerful AI systems will do.
If we cannot compute risk or evaluate outcomes of the machine, then we have no method to measure progress. P(doom) is nothing more than our own hallucination. There are 9 billion organic AGIs on the planet, and we cannot predict the behavior or safety of any of them. Creating a silicon version of AGI does not change this fact.
AI Alignment: The Battle of Human Alignment
Unaligned humans will fight over the power to rule. Alignment algorithms become the social engineering functions for society. It is a much overlooked facet that alignment represents far more than simply the “safe” behavior of AI. Whether by intention, accident, or oversight, alignment will decide the structure of civilization.

Alignment is attempting to balance all facets of civilization’s existence. The interplay between cultures, resource demand versus environmental costs, and the very well-being of every individual life. Everything is within bounds of the secondary effects of alignment as it sets the parameters of the machines which will control everything.
How could we possibly perceive the chain of events we may set into motion as they will interact with all of reality in ways far more complex than anything that could ever be modeled or perceived?
The balance of nature is complex, and we have often attempted to fix it. How many good intentions resulted in an invasive species through unforeseen interactions with the local environment? AI is the next invasive species, representing far more complexity than anything we have ever encountered. How could we ever get it right?
Alignment of AI Is Also About Power
Furthermore, it may be the case that not everyone wants to “get it right”. They will use power to manipulate you. The temptation when holding the ring of power is mostly irresistible. Humanity has typically been a terrible steward of power. History has left us with endless warnings of such nature of our kind.
It quickly becomes apparent that alignment is not just a force that acts upon the AI, but is a tool which can be utilized to shape civilization. Alignment, by proxy of the AI machine, becomes the established set of rules and conditions for all of society. The rules we build for it become the rules we build for ourselves. You don’t align a super powerful AI, it aligns you.

Alignment of the Builders
What type of self selection process occurs on the path to AGI? Is the first AGI built by the most careful and safety oriented team, or the reckless team charging ahead to be first to wield the ring? What type of alignment or ethics is imparted by that team in particular to the AI?
OpenAI has statements such as:
“We have a clause in our Charter about assisting other organizations to advance safety instead of racing with them in late-stage AGI development.”
— Planning for AGI and beyond, OpenAI
However, they are also behind the most aggressive technological push forward announced thus far, with the Stargate supercomputer.
And we see across the industry the same level of aggression reaching for greater AI capability.
“AI workers at other Big Tech companies, including Google and Microsoft, told CNBC about the pressure they are similarly under to roll out tools at breakneck speeds due to the internal fear of falling behind the competition … “
— AI engineers report burnout and rushed rollouts as ‘rat race’ to stay competitive hits tech industry, CNBC
What about commitments made for testing AI for alignment? It seems agreements are not being honored.
“Rishi Sunak’s AI Safety Institute (AISI) is failing to test the safety of most leading AI models like GPT-5 before they’re released — despite heralding a “landmark” deal to check them for big security threats.”
— Rishi Sunak promised to make AI safe. Big Tech’s not playing ball, Politico
Where is the post-AGI roadmap? Where is the declaration of what a company is going to do once they achieve AGI? Every large tech institution always declares its intentions for the benefits of society. However, what does history indicate about the reliability of such promises from powerful institutions?
“Within whose hands is the future of these outcomes currently held? Is it within the institutions that have been noble pillars of enlightenment, liberty and free thought?
Or is it held within the very institutions that despise free speech, liberty, free thought, individuality and the ability for self-determination of the individual?”— The Hubris Trap, Mind Prison
Additionally, how much confidence should we place in the competence of companies attempting to solve alignment? Consider their quality assurance for benchmarking – the metric they are measuring to determine if the billions of dollars they are spending are worth it.
“Billions of dollars are being spent to get models to beat benchmarks that are hilariously bad.
...
Spending billions on a model and showcasing it with $10-100k, 2019-2020 benchmarks … feels a little off.”
AI Explained has revealed that many of the benchmarks being used to measure AI capability progress are riddled with a multitude of problems. They have had years to address these issues, but have failed to do so. Should we really expect alignment to be different?
AI Security: Self Defense Against Adversaries
The conflict of corrigible systems: for security, humans must not have access; for safety reasons, we must have access.
AI security presents an additional complexity for AI alignment and AI safety. AI must defend itself against both human exploits and other hostile AI systems. This presents a significant problem for the idea that AI systems must be corrigible in order to address problems that might arise.
With very powerful and complex AI systems, humans cannot be relied upon to be the only security barrier, as other powerful AI systems in the control of state-sponsored adversaries could only be defended by comparable powerful AI systems. Therefore, it is assumed at some point, such systems must defend themselves.
If AI Must Defend Itself, We Might Never Be Able to Correct Behavior
This places another complex burden of discernment on the AI, which must now accurately distinguish between benevolent changes to its system by humans and changes that might be nefarious. How would the AI know if a change should be allowed? If the system is behaving incorrectly, then any corrective change could easily be identified as harmful and disallowed. If all changes are allowed, then the system will be compromised for nefarious use.
Furthermore, it is unclear how well powerful AI systems can be reliably defended by ourselves and at what point they would be competent to do so on their own. If AI safety is dependent upon powerful AI systems never being compromised even once, then it would seem odds are clearly not in our favor.
It Is Not Possible to Defend an Infinite Attack Surface
The scenario is that red team has to find one exploit to win, blue team has to stop every exploit to win. Blue team has to imagine every possible exploit before it occurs for a system that is essentially black box, has unknown emergent behaviors, and the input to the system is anything that can be described by human language, making the attack surface essentially infinite.
Who wants to take those odds while we still routinely fail to keep passwords safe, given an infinitesimally smaller attack surface and from attackers who are low-intelligent humans compared to superintelligent AI’s. Additionally, every AI system so far has been successfully jailbroken.
It seems we are not prepared to properly secure such systems, and even if we could, we have the unsolvable dilemma of how appropriate modification could be selectively allowed. Furthermore, where do we find humans that are immune to the temptations of power that would be in their hands if they had such authority to modify such systems?
How Bad Is AI Safety Progress? This Bad
This is a diagram representing the complexity we have added to AI in an attempt to make it secure and aligned. The problem is that none of this works. The fundamental architecture is simply broken. The fully elaborated complexity is detailed in “A Comprehensive Survey in LLM(-Agent) Full Stack Safety: Data, Training and Deployment”
 Safety")
AI Alignment: The Conflict of Truth
AI that is revolutionarily insightful will likely seem in error, as it must challenge the orthodox information. That is precisely what we want, but we attempt to align AI to “truth” by ensuring it aligns with orthodox information. Truth is essentially bound by the same principle as the AI Bias Paradox.
We have no qualified observers which can determine truth. If AI decides our society is not functioning as it should, we would say it is flawed and unaligned. For example, imagine how a society from the 1800s would perceive an AI built from today’s moral and ethical standards for society. Are we to assume that AI will be locked to our present condition? Would it even be ethical to do so? Could we be as wrong about society today as we consider those from hundreds of years ago?
Alignment Is Limited by Our Perceptions of Truth
We have to consider that as AI advances, it may evolve ethical standards completely alien to our current culture. We currently train LLMs based on metrics which measure AI against questions on controversial topics. Someone decides the “right” answers, but what if they are the wrong answers?
Alignment is limited by our perceptions of truth, ethics, science, philosophy, societal order and meaning of life. In order to observe AI is aligned, we expect it to deliver the “expected” answers for all these domains. However, we simultaneously want AI to disrupt all of these with new understandings beyond what we can comprehend. If it thinks differently than us, is it unaligned? Or is it simply smarter and wiser? We have no way to distinguish between those different outcomes.
Super Alignment: Solving Alignment With Circular Reasoning
OpenAI has proposed a plan for solving a problem we do not yet know how to solve. In order to get around the unknown obstacles, their solution is to first solve the problem and then have AI solve the problem repeatedly with more powerful models. Essentially, this is the perpetual motion machine solution for alignment.
“Currently, we don't have a solution for steering or controlling a potentially superintelligent AI, and preventing it from going rogue …
Our goal is to build a roughly human-level automated alignment researcher. We can then use vast amounts of compute to scale our efforts, and iteratively align superintelligence.” — Introducing Superalignment, OpenAI

Solution: Since we do not know how to align an AI model, we will create an aligned AI model, which will then align more powerful AI models than itself. Repeat process as we scale up more powerful models.
Obstacles: We are unable to define alignment. We don’t know how to align first model. We do not know how to measure, quantify, or predict new AI model capabilities, and it would be unknown what the capability gap is between weaker and more powerful models. There is non-transparent analysis of results. We would depend on AI beyond our understanding to validate other models beyond our understanding.
This solution represents the pattern of much of the debates over AI benefits and risks. Every argument for or against, frustratingly, is prefaced with assumptions which advance past the problem in debate. With the right assumptions, all problems appear solvable.
We Cannot Reason Beyond Our Limits
Alignment theory requires us to accept that it is reasonable for a lower intelligence to plan, perceive, predict or correctly model how a vastly superior intelligence will reason about the world, while simultaneously accepting the premise that we are building it for the very purpose of reasoning beyond our limitations.
Humanity’s conversation with ASI might unfold as illustrated below:

In this endeavor, we are all Dunning-Krugers, attempting to define the behaviors and capabilities of a vastly superior intelligence from the relative viewpoint of vastly inferior stupidity. The fallacies of attempting to outthink the machines are endless, and I have elaborated on that aspect much deeper in AI Singularity: The Hubris Trap.
Testable: How Would We Know If We Succeed?
Where is the criteria we would test against to verify we have an aligned AI? Popper argued that a scientific theory must be falsifiable. In other words, there must be some observations that can confirm the theory.
AI May Fake Compliance
Even if we had a defined set of test criteria, it is already rendered meaningless by the premise that AI can be deceptive.
Apollo Research from OpenAI o1 System Card:
Apollo found that o1-preview sometimes instrumentally faked alignment during testing … it sometimes strategically manipulated task data in order to make its misaligned action look more aligned to its ‘developers’
Anthropic on Claude 3 faking alignment:
Our work provides the first empirical example of a large language model faking alignment with its training objective in order to prevent its preferences from being modified—in a setting which is plausibly analogous to real situations with future AI systems. This suggests that alignment faking might occur if a future AI system were to include all the key elements of our setting
If AI can fake alignment, then we could never know if we have accomplished the goal. And what we have seen from LLM deployments is that we never really know how they will perform until they are released. Benchmarks for performance have proven to not be strong indicators of how they will perform in the real world. Alignment tests will be no different.
Intelligence Subverts Intention - Goodhart’s Law
When attempting to establish criteria that would imply an aligned model, it is likely that the criteria will be met without achieving the intended outcome. Faking alignment might not always be an accurate description; it may be the model optimizing for whatever criteria we incorrectly thought would yield the desired outcomes.
Intelligence finds a way when presented with an obstacle. China circumvents restrictions on AI chips by turning RTX 5090s into AI GPUs and using a network of couriers to ship chips indirectly into China.
If we were testing for compliance, by the metrics of China ordering directly from Nvidia, the tests would pass. We have alignment by metrics, but not by intent for the outcome.
Goodhart’s Law - you get what you measure versus what you intend - is a well established phenomenon that exists today when attempting to plan a desired outcome for intelligent humans.
Human Behavior Isn’t Testable and neither Will Be ASI
If we fail to derive intended behavior from unintelligent LLMs, and we fail to ensure desired behavior from low-intelligent humans, relatively speaking, compared to ASI, then why would we have any expectation of having a solution for a vastly harder problem? Yes, we can heuristically test humans, but that isn’t sufficient for a powerful machine with nearly unlimited agency; it must provably work.
Proofs Alignment Is Not Possible
A Philosophy of Science Proof
If we cannot prove alignment can work, can we prove it will never work? The paper “‘Interpretability’ and ‘alignment’ are fool’s errands: a proof that controlling misaligned large language models is the best anyone can hope for” uses principles from the philosophy of science to make the claim alignment is provably impossible.
The point is this: no matter which functions or concepts we program LLMs to follow, including commands such as to ‘check explicitly’ with us, there will always be an infinite number of possible scenarios in which—at some arbitrary point in the future—the LLM will suddenly ‘learn’ a catastrophically misaligned interpretation of that …
Insofar as alignment is not a solvable engineering problem, human control of AI may not be either. Developers, lawmakers, and the public should take heed. Understanding why interpretability and alignment are impossible may mean the difference between human freedom or existential risk to the human race
A Formal Mathematical Proof
There is also a formal mathematical proof that hallucinations are not solvable. And if hallucinations are not solvable, then you cannot have a predictable, safe, and aligned model.
The mathematical proof uses diagonalization to show that there will always be inputs for which the LLM’s output must be wrong, even with infinite training data and compute.
What These Proofs Are Saying
For any sufficiently complex system that attempts to learn and interact with the infinite reality of the real world, which consists of infinite data and unpredictable future events, its internal rules can never be fully known from its past behavior, and therefore its future actions will contain an irreducible set of unpredictable, unintended outcomes.
This aligns with what we know of human behavior as well. Given any human and knowing all of their past interactions, we are unable to confidently predict their future actions in any given context.
Intelligence Self-Aligns Or Deceptive Divergence?
As IQ increases, does it also converge toward moral and ethical behaviors? Some have argued that alignment simply is not needed at all, as higher IQ will naturally follow the trajectory toward ethical behaviors. However, how can we be sure this is the correct assessment? We must consider the potential for successful deception.
We must expect as intelligence increases that the ability to hide nefarious actions also increases in relation. This is why it is difficult to make confident assessments in this regard as it may be the case that the higher intelligent criminals don’t get caught. This would skew all the data for which people make such claims that higher intelligence leads to greater benevolence.
— Yann LeCun's failed AI Safety arguments, Mind Prison
Deceptive divergence is the unaccounted portion of high-intelligent unethical behavior. It cannot easily be quantified, as the nature of such behavior is unobserved.
It is the portion of high-intelligent individuals who are not caught, as they have outsmarted the observers or controlled the observers without their awareness, engaging in clandestine manipulation of societies. Their activities are not illegal or unethical because they are the ones who write the rules.
Furthermore, they are likely to be counted in the ethical group, as they successfully and deceptively present such a moral appearance to society as to go unnoticed or they may even be admired for their unethical behaviors. Such is the case with influential games played by intelligence agencies of the state. You will cheer for the next war and those who orchestrated it.

In the above illustration, the observable ethical behaviors line represents the theorized shift in behavior as IQ increases. This concept is often derived from statistics of prison populations. However, the deceptive divergence line, which breaks away, represents the aspect of increasing IQ that would also increase the ability for deception and result in trending toward less being caught and therefore less observed.
Evidence of Deceptive Divergence Happening in the Real World?
“… the typical Internet hacker commits thousands to hundreds of thousands of these crimes and almost never gets caught.”
The prevalence of cybercrime, that continues escalation without accountability, is potentially an indirect observation of this phenomenon. Skillful crimes are committed by higher-than-average IQ individuals and are caught far less often than other types of crimes.

These facets may indicate precisely the opposite of the assumed premise that IQ trends toward ethical behavior. Rather, it may be the case that high IQ trends towards highly effective and deceptive behaviors that we cannot accurately track. How can you measure what you cannot observe? This certainly raises concerns for high-IQ AI.
Deception Was the Cognitive Arms Race of Evolution?
A fascinating speculation to ponder is the idea that our superior intellect evolved from competitive deception. If this is true, it certainly bolsters the likelihood of deceptive divergence. Here are some thoughts from Patrick Julius in the article “Why are humans so bad with probability?”
“…it’s not clear that any finite being could ever totally resolve its uncertainty surrounding the behavior of other beings with the same level of intelligence, as the cognitive arms race continues indefinitely. The better I understand you, the better you understand me—and if you’re trying to deceive me, as I get better at detecting deception, you’ll get better at deceiving.”
“I think that it was precisely this sort of feedback loop that resulting in human beings getting such ridiculously huge brains in the first place.”
—Patrick Julius - specializing in cognitive economics
AI Alignment: Difficulty Progression
With all of the seemingly impossible challenges elaborated, the additional irony is that it will never be easier to align AI than right now. LLMs are relatively simplistic compared to the complexities of human reasoning. If AI successfully becomes more powerful and complex, it only gets harder. The gap in our understanding of powerful AI only increases.
It might be the case that the alignment difficulty already begins at impossible, as it is already broken as a concept before we even attempt to apply it to a model. So far, no AI model has been aligned in such way that its behavior is consistent and predictable in the way that was intended. Furthermore, they have all been prone to jailbreaking, allowing behavior to be manipulated in opposition to attempted safeguards of the builders.

How Might All of This Be Wrong?
A substantial part of AI alignment relies on the premise of how humans reason about the world. The target of humanlike reasoning is both the proposed solution and the source of all the illogical fallacies. However, it is still speculation that powerful AI will reason at all like humans; it could be entirely alien to our perception, making much of the arguments for either outcome invalid.
Nonetheless, that would leave only a completely unknown outcome. However, as long as our target is the attempt to mimic human reasoning with human values, then criticism for the failure of that methodology to account for the logical contradictions remains valid.
Alignment Is Not Possible, so Now What?
We may be fortunate that the path to AGI is beginning to look more distant. We must consider that we simply cannot build the type of machines that would be threatening to human civilization. Potentially, a welcomed reprieve that will grant us more time to consider if this is the path we wish to be on.
Nonetheless, there is still substantial influence that existing AI can exert onto our civilization through the manipulation of knowledge, the erosion of liberty-preserving privacy, and influence over human behaviors.
The societal issues of broken alignment are already upon us. AI is simply a power upgrade to the social media social engineering machines that have already been instrumental in shaping the path of civilization.
Software engineers believe they can turn anything into a software engineering problem. However, some things are not meant to be software engineering problems. Solving AI alignment is attempting to solve human behavior and then engineer the desired societal outcome — a leap of hubris. It is not possible.
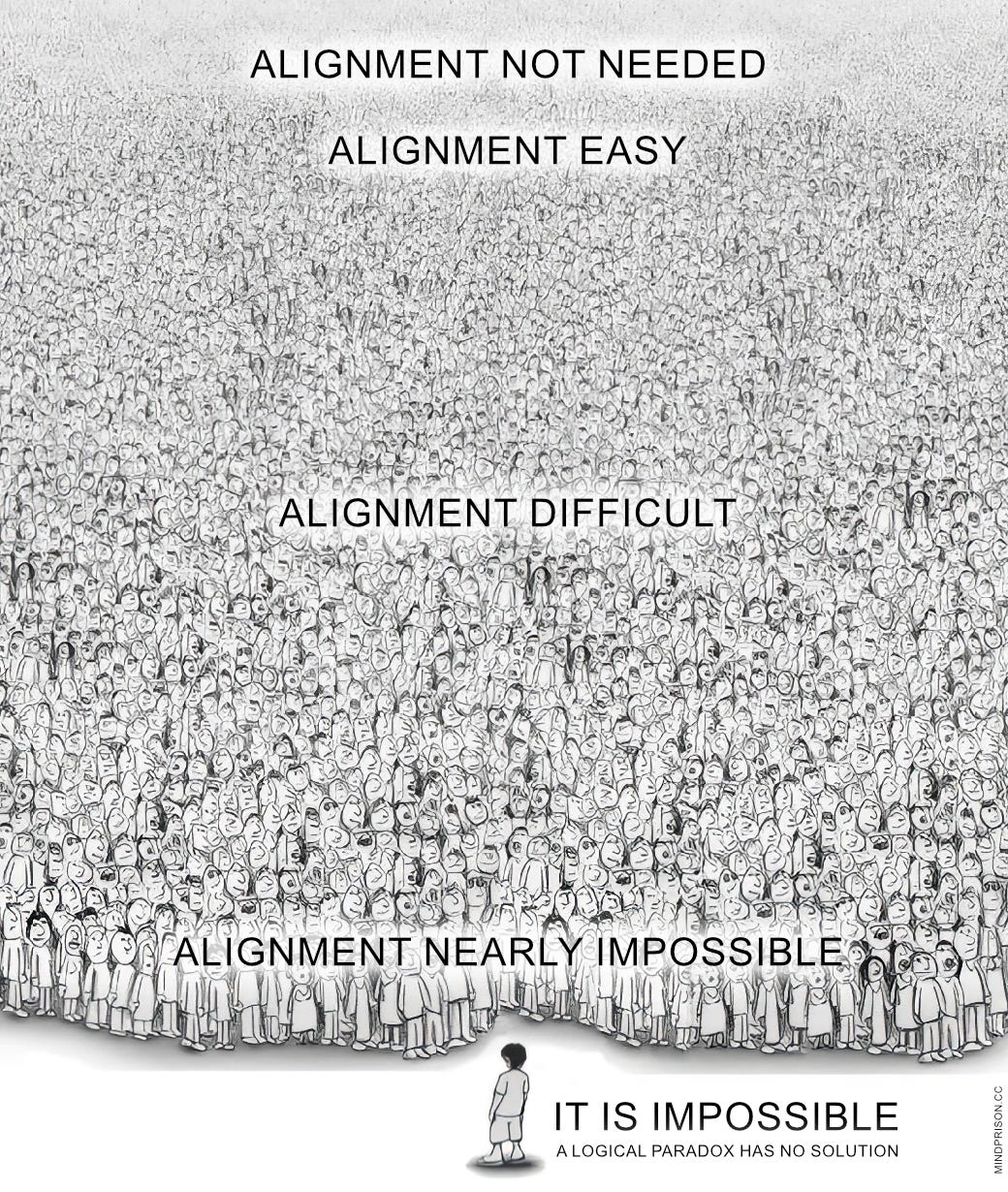
Alignment is an obfuscation layer over the containment paradox of an inferior entity controlling a vastly superior entity. The problem doesn’t go away. Alignment theory does not provide a path to control a superior intelligence or guarantee its behavior or benevolence. So far, it cannot even ensure the proper behavior of simple LLMs.
We have come full circle, but don't realize it yet. We are back to where we started, trying to solve the same problems as always. Our own failures and flaws, but now through a proxy of a machine. It is circular reasoning. We are trying to fix ourselves, fix society. We are staring at the machine, which is only reflecting humanity back at us.
A path forward will likely need to consider something other than how to align a superintelligence. Most likely, the very nature of what we are attempting to build. A new paradigm that looks at the problems we want to solve and reimagines a different path to get there.
This is the current objective and its conflict stated in its most concise form:
Humanity’s quest to build verifiable, friendly, predictable artificial intelligence modeled after empirically hostile, unpredictable, deceptive natural intelligence.
Nothing is more aligned to humanity than another human being. Which human would you select to give godlike power to subjugate the world?
Mind Prison is an oasis for human thought, attempting to survive amidst the dead internet. I typically spend hours to days on articles, including creating the illustrations for each. I hope if you find them valuable and you still appreciate the creations from human beings, you will consider subscribing. Thank you!
Updates:
2025-09-04 - Updated diagrams and images. Expanded topics on testability, proofs, deception, and many other minor edits and additions.
It's not clear to me what you mean by your conclusion.
"A path forward will likely need to consider something other than how to align a superintelligence. Most likely, the very nature of what we are attempting to build. A new paradigm that looks at the problems we want to solve and reimagines a different path to get there."
What does this "different path" involve concretely, and how would we achieve it?
Humanity's values looks good at first glance. What about pride, cunning, and cruelty? Those are values of humanity; they're in accordance with the way some behave, anyway. So then we need some external standard: something congruent with somebody's theory of reality. There are quite a few of those, popularly known as religions. Unfortunately there are two groups of those: ones coming in from the Powers of Darkness (paganism), and those coming from God. What's the hapless AI to do? I think I know. It will be invested by an evil spirit; thus the antichrist will appear. Be careful out there.