Notes From the Desk are periodic posts that summarize recent topics of interest or other brief notable commentary that might otherwise be a tweet or note.
What if AGI is not coming?
No matter what appears to be happening, we always have to consider what if it isn't. What If LLMs fail to turn into AGIs? Has our quest for intelligence simply unveiled our demonstrable lack thereof? Will trillions of dollars turn unpredictable hallucination machines into reliable universal productivity tools that can do anything?
When it comes to hard problems the herd is almost universally always wrong. There is an enormous amount of institutional money flowing into AI development on the premise that LLM architecture is going to manifest something we call AGI that will solve all the world’s problems.
So what are some of the counter perspectives?
These are the primary arguments that are expanded below:
We will soon be reaching the limits of hardware scaling for larger AI models.
There have been no major AI technology breakthroughs in decades. Everything we are seeing is larger compute scaling.
Scaling alone is not going to create AGI, need other novel discoveries.
The release of ChatGPT to the public made people think that generative AI was just getting started on an exponentially improving curve.
Yet, generative AI itself had been around for a while before that & what we are seeing is probably the best it will ever be.
Of course improving past what GPT-4 is now is going to require more & more resources to the point that no company, however big, will have the incentive to improve the technology any further.
Until a new breakthrough comes along, generative AI is almost at its peak now.
If Google struggled hard to make a model based on performance in the class of GPT-4, do you honestly think there is more juice in generative pretrained transformer (GPT) models to keep pumping out more improvements?
I don't think so, these models are already too big.
…
Therefore GPT-4 is right at the elbow of the S-curve given the sort of diminishing returns already being observed - language models, both closed & open source, aren't improving as much as they are demanding more & more resources such as compute & data.
A deep neural net (DNN) is just an arrangement of simple nodes - the perceptrons from the 40s, with various nonlinearities - in layers one atop the other.
AI companies are hoping that if they can mega size these DNNs by using lots of compute & data they can solve intelligence.
The foundation for DNNs was layed out in the 80s.
Gradient descent (GD) was around even much earlier than that, stochastic gradient descent (SGD) is a variant of GD. For GD, the gradients are computed by passing through the entire training set before taking a step. SGD uses one sample - drawn randomly from the training set hence the term stochastic. Batch GD uses a greater than 1 sample but not all samples to compute gradients.
There are variants to help convergence faster to a solution. But nothing much has changed.
…
Thus if you look at it, there hasn't been enough innovation other than just mega sizing old 80s techniques using modern hardware. The success of today's systems are more attributed to breakthroughs in hardware computing like GPUs, TPUs etc than actual AI algorithms.
That's why you expect AI to hit a plateau soon because mega sizing these models has limits. Physical limitations will come into effect to prevent further scaling up. No matter how much compute or data they through into these, they won't solve intelligence.
We still do not have good methods to understand capability
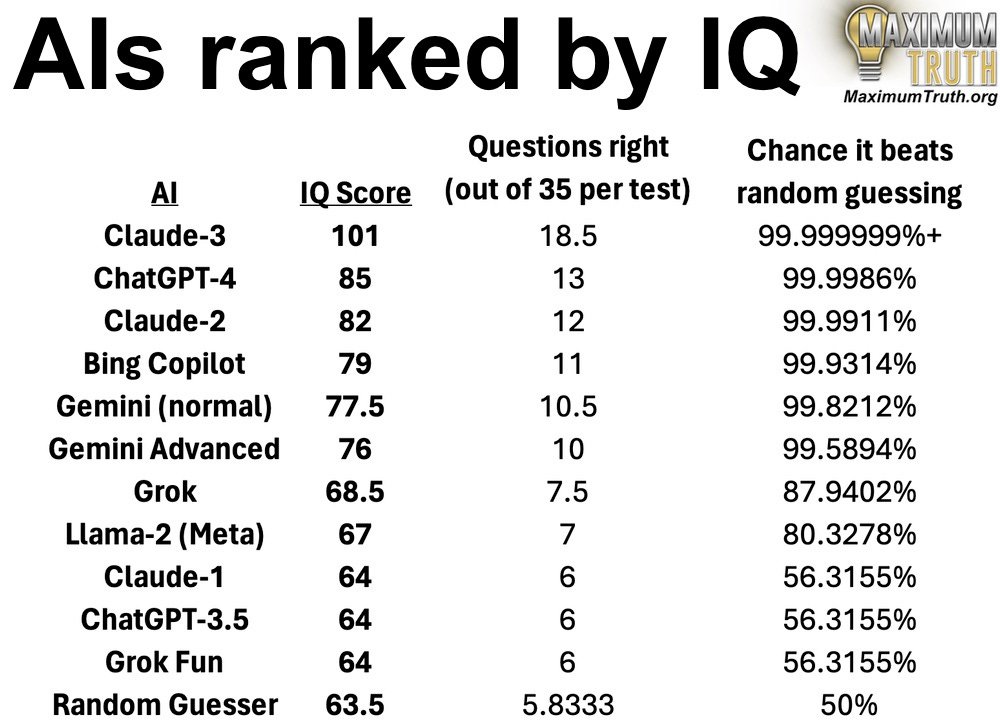
This suite of tests from Maximum Truth demonstrates the trouble of measuring the “IQ” of LLM intelligence.
The new Claude-3 scores 101 the highest of any LLM so far. However, Claude is still a strange mix of capabilities in that IQ measurements give us no hint as to how Claude performs. It still fails to answer basic questions and hallucinates, but at the same time has proven to solve far more complex problems than other models.
Here is Claude-3 failing to answer correctly the relative weight of feathers and bricks: How many more billions of dollars of compute will solve this one?
And here is Claude-3 solving novel problems:
IQ tests don’t predict this type of divergence in expected capability and it is exactly this that continues to create such divergence in opinion as to whether we are getting closer to AGI or making very expensive and unreliable Dr. Jekylls and Mr. Hydes.
Why we might reach AGI anyway
Billions to trillions of dollars will be poured into research over the next decade. More humans than ever are looking for breakthroughs. We have exponentially increased the parallel efforts. LLM architecture might be unable to deliver AGI in its current state, but it has ignited monumental investments into research that might find other paths.
However, expectations have been set extremely high. AI is the perfect technology that is currently just good enough to excite the imagination of what it could do making it seemingly within grasp but potentially still far away. It is the problem of being almost there seemingly indefinitely. Despite the real utility of current LLMs, the promises are far greater and if not delivered will result in significant market collapse in due time.
Does everything stop if there is no AGI?
Without AGI we are still exponentially improving, just not vertically with intelligence, but horizontally as new applications and methods are discovered for its use. Refinement in training, data, inferencing and application are all still advancing.
If we are not intelligent enough to know what is intelligence, then just how intelligent are we? And are we intelligent enough to build more of something that we don't know what it is?
No compass through the dark exists without hope of reaching the other side and the belief that it matters …
Mind Prison is a reader-supported publication. You can also assist by sharing.
I think the whole chase for AGI is ridiculous. It's the same red-herring chase as the whole climate change chase. There is no definition of what AGI is, nobody known how to define consciousness but here they are "chasing" it. It's just a money grab and pure marketing is all it is.










I think the whole chase for AGI is ridiculous. It's the same red-herring chase as the whole climate change chase. There is no definition of what AGI is, nobody known how to define consciousness but here they are "chasing" it. It's just a money grab and pure marketing is all it is.